openinfer
A from-scratch LLM inference engine in pure Rust + CUDA. OpenAI-compatible. Serves Qwen3 to Kimi-K2.
Highlights
Section titled “Highlights”- No Python at runtime — no PyTorch, no ONNX, no framework in the serving path.
- Five model lines, one engine each — Qwen3 through Kimi-K2.
- Up to 8-GPU expert parallelism for large MoE deployments.
- OpenAI-compatible API — point any SDK at
http://localhost:8000/v1.
See the getting started guide or the GitHub repository.
Quick start
Section titled “Quick start”git clone https://github.com/openinfer-project/openinfercd openinfercargo run --release -- --model-path models/Qwen3-4BThen send a request:
curl -s http://localhost:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{"prompt": "The capital of France is", "max_tokens": 32}'- Speculative Decoding (2026-07-17) — From output entropy and verification correctness to EAGLE draft models and dynamic verify length.
- See Qwen3 Decode as a CUDA Graph (2026-07-10) — Export the live decode graph as a detailed DOT and a folded high-resolution PNG.
- Co-locating Prefill and Decode on One GPU (2026-06-20) — CUDA Green Contexts for stable decode latency without losing throughput.
- OpenInfer 0.1.0: Production-Grade Rust Inference (2026-06-13) — Architecture, footprint, cold-start, and RTX 5090 serving benchmarks.
Footprint
Section titled “Footprint”No PyTorch, no JIT, no runtime compilation. The whole stack — weight loading, paged KV cache, schedulers, kernels — is Rust + CUDA from scratch. Resident memory stays a fraction of vLLM’s at the same load.
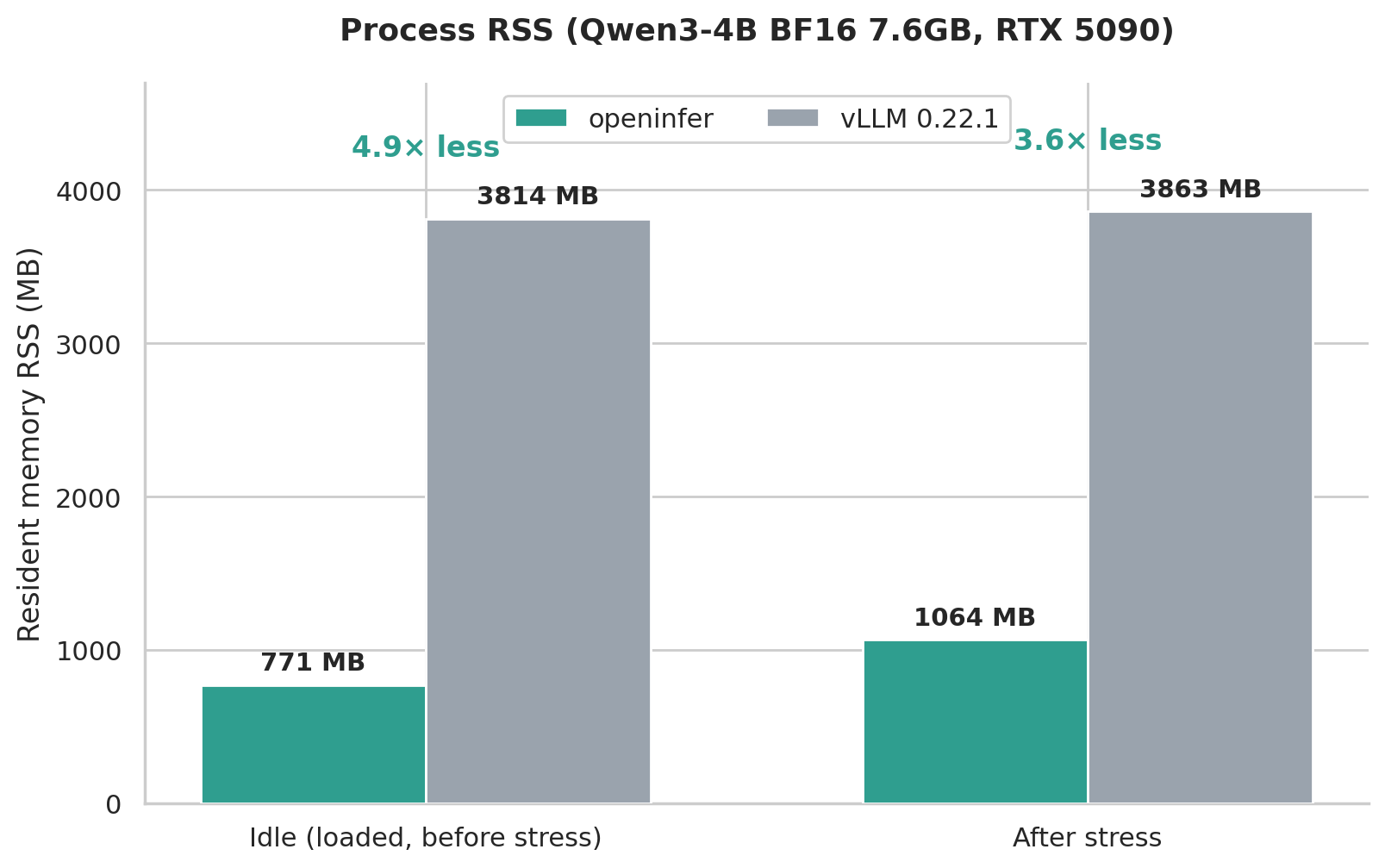
Process RSS · openinfer vs vLLM · Qwen3-4B BF16
Startup
Section titled “Startup”3s warm start vs vLLM’s 32.7s — about 11×. No runtime compilation, no JIT warmup: once it’s built, what ships is stable and predictable.
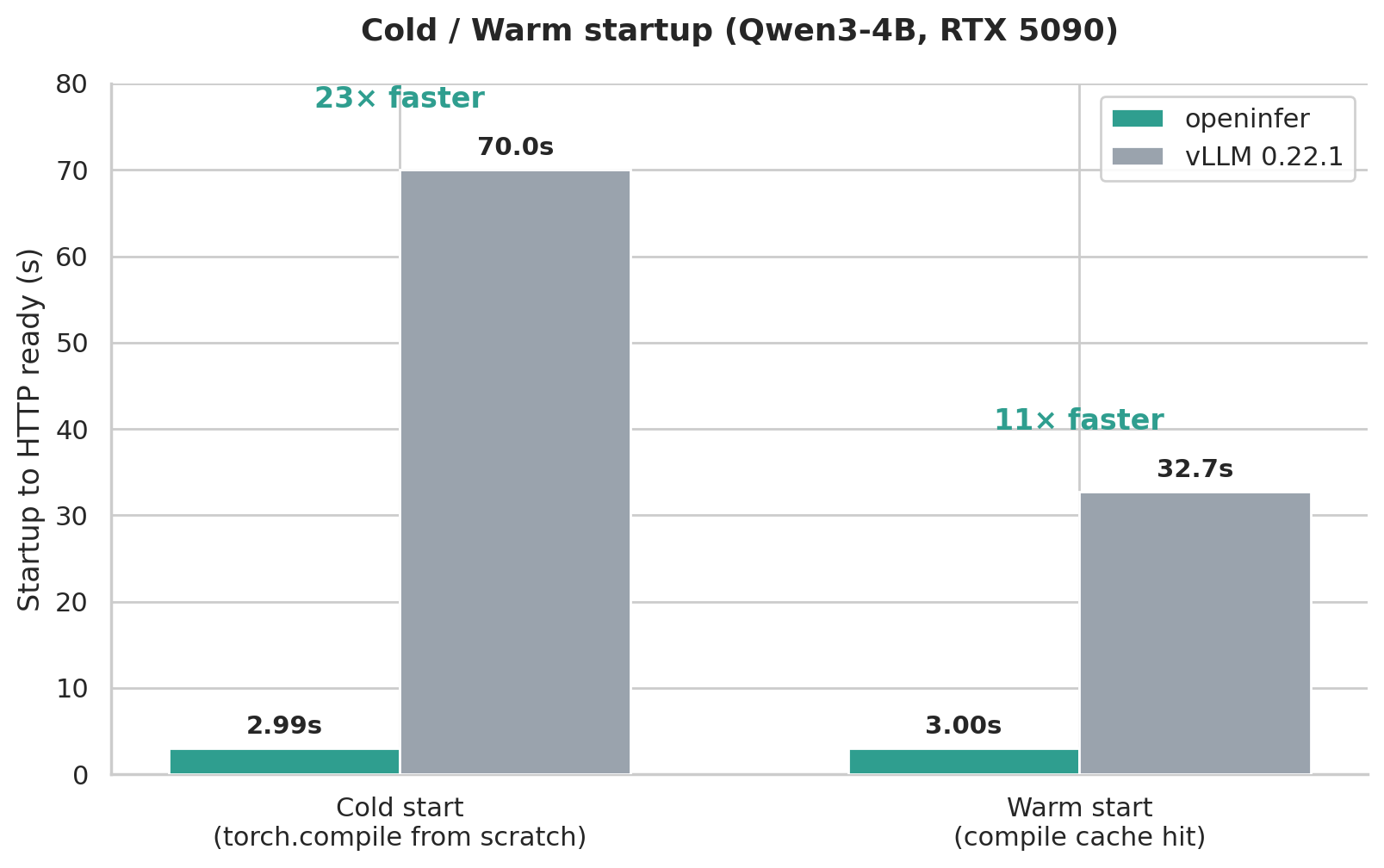
Warm start · openinfer 3.0s vs vLLM 32.7s
Throughput
Section titled “Throughput”Same vLLM bench-serve client, same Poisson arrivals, same seed on RTX 5090. At the saturation point openinfer pushes 6% higher throughput than vLLM 0.22.1.
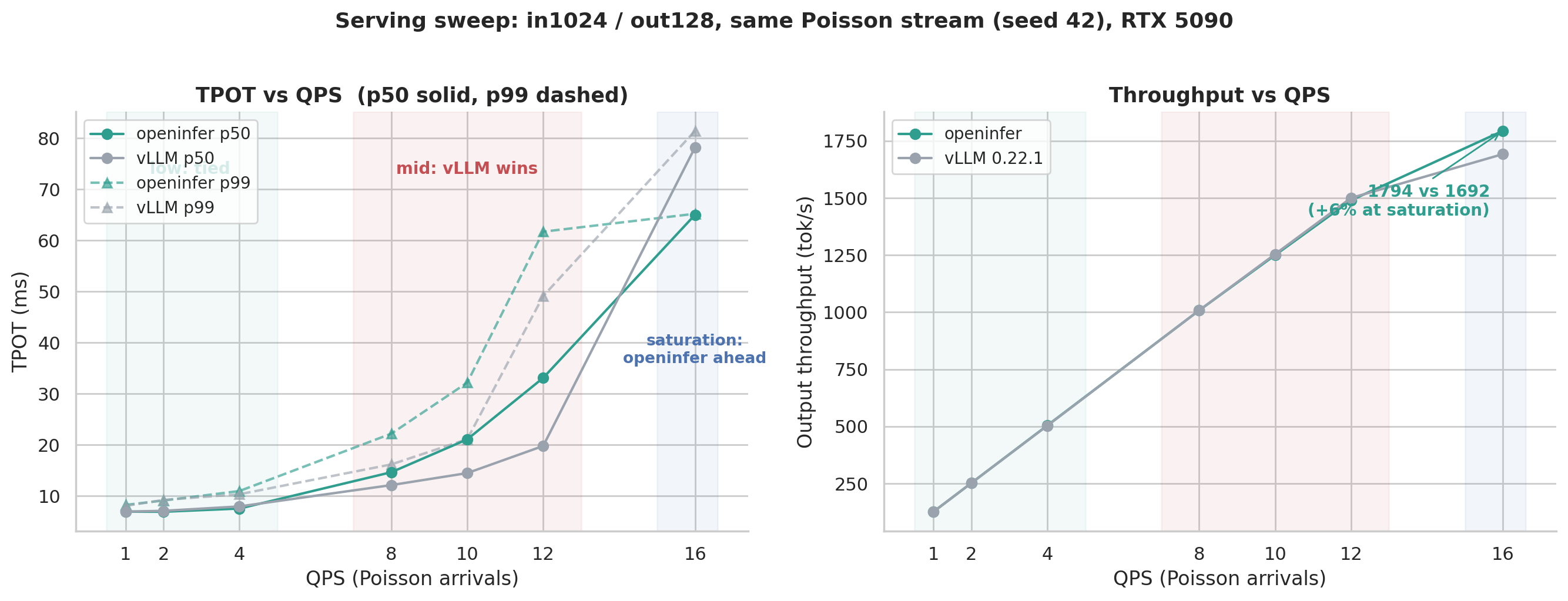
Serving sweep · RTX 5090 · vs vLLM 0.22.1
Decode
Section titled “Decode”Decode is captured as a CUDA graph with pre-allocated buffers, keeping per-token overhead low and decode latency flat across context lengths.
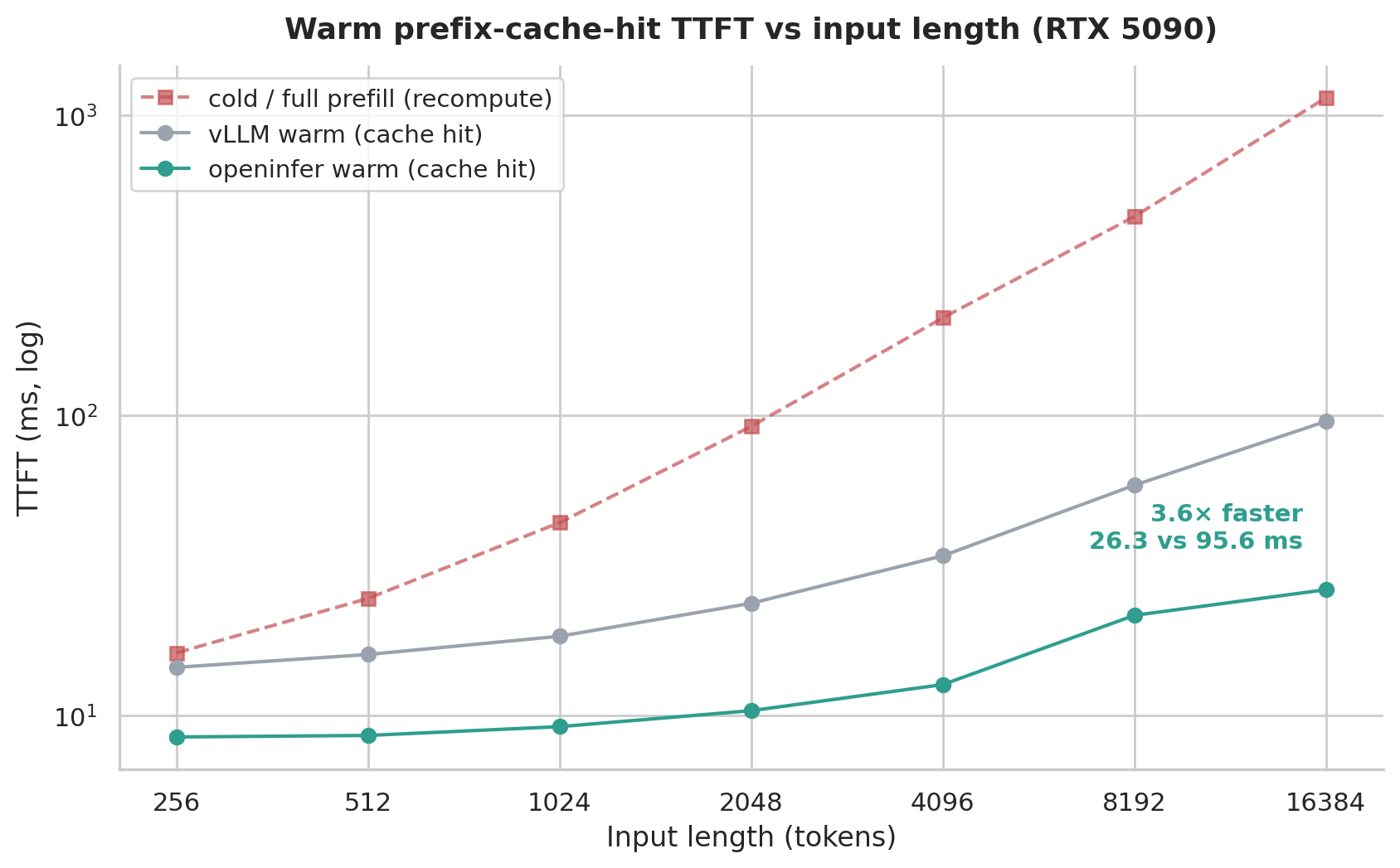
Warm prefix-cache TTFT · by input length
Supported models
Section titled “Supported models”| Model | Architecture |
|---|---|
| Qwen3-4B / 8B / 32B | Full attention, tensor parallel |
| Qwen3.5-4B | Hybrid: 24 linear + 8 full attention layers |
| DeepSeek-V4 | MoE + compressor + indexer, 8-GPU |
| DeepSeek-V2-Lite | MoE + expert parallelism, 2-GPU |
| Kimi-K2 | MLA + MoE + Marlin INT4, 8-GPU expert parallelism |